Building a Mini Hadoop Cluster for Fun
What started as a fun side project—setting up a Hadoop/Spark cluster with physical mini PCs—turned out to be surprisingly useful later when I repurposed it as a Kubernetes dev cluster at work.
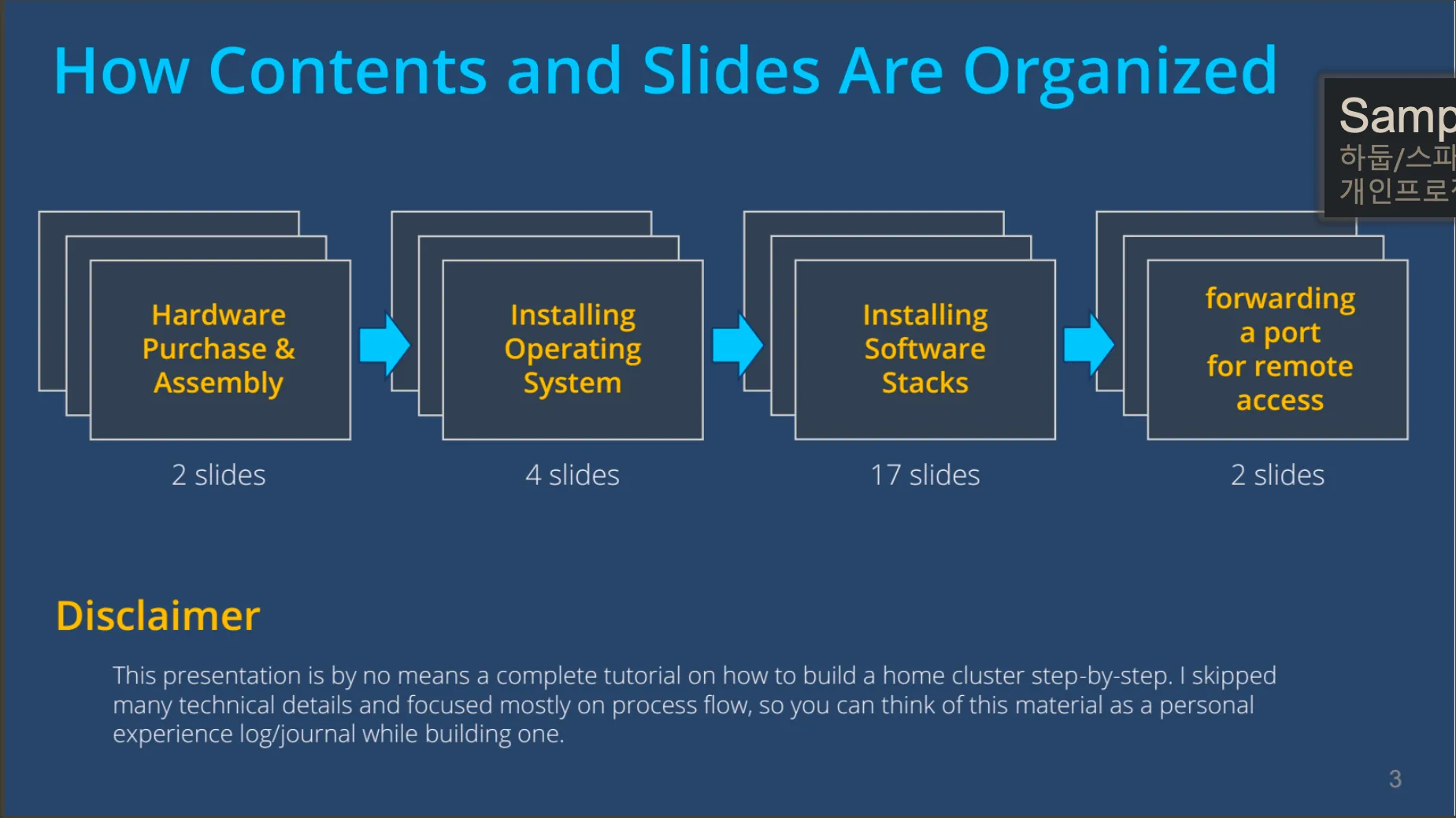
Back in 2016-2017, I was completely fascinated by the world of distributed computing—especially with tools like Hadoop and Apache Spark. The idea that a cluster of machines could work together to process massive datasets—scaling computation across nodes like a little data center—was just too cool to ignore.
Sure, I could’ve set everything up using virtual machines on a laptop. But instead, I went the “fun” (read: expensive and unnecessary) route and built a physical Hadoop cluster using four mini PCs—one for each node. Looking back, it was absolutely overkill, but it made the project all the more enjoyable.
I configured everything manually:
- Chose CentOS as the Linux distro
- Tuned CPU fan speeds (those tiny machines could get loud!)
- Assigned Hadoop and Spark daemons across nodes
- Set up RStudio Server on one node so I could interact with HDFS and submit Spark jobs through R
Although I didn’t get much practical use out of the cluster at the time, it laid a solid foundation in distributed systems, and I learned a ton about networking, cluster orchestration, and data infrastructure.
In fact, I ended up repurposing the same hardware later on as a Kubernetes dev cluster, which turned out to be incredibly handy during my early engineering career.
Sometimes you build something just for fun—and it ends up paying off in ways you never expect.